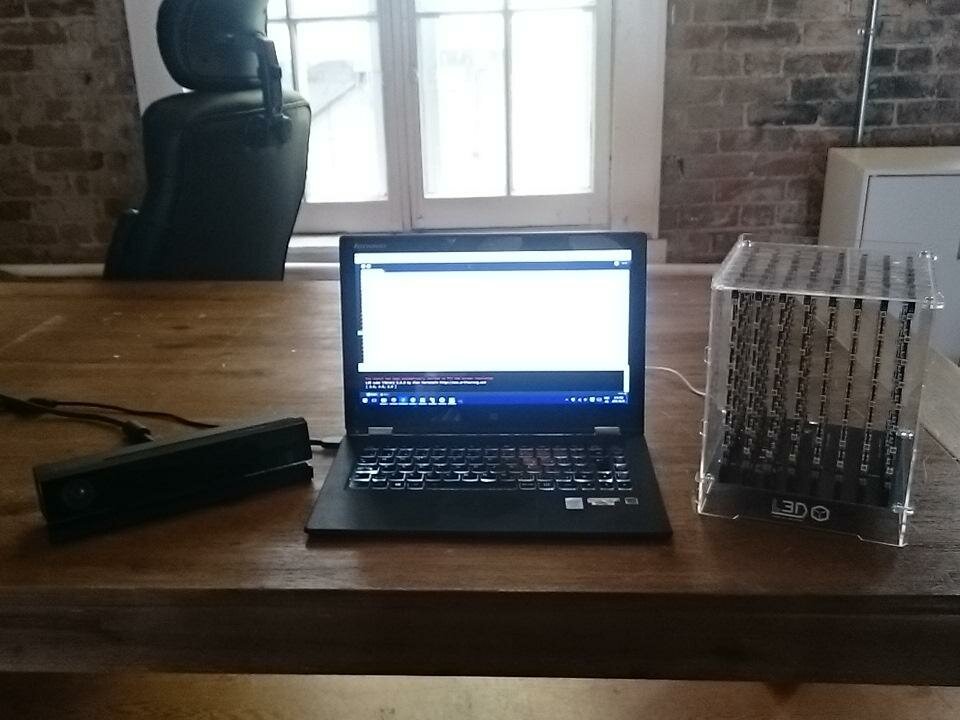
Overview
The Kinect is a traditional camera doubled with an Infra Red Camera, enabling it to perceive depth in addition to the color information.
Originally sold for Xbox, it is now available for PCs under the brand Kinect for Windows. Don’t let the name fool you, it will work just as well on OSX or Linux.
Similarly to what we did for the webcam, we connect to the video stream of the Kinect, analyze each frame and downsize them so that they can be displayed on the cube’s 8*8 resolution.
But this time, we will also extract the depth information that the Kinect returns along with the color information of every pixel. In the same way that we averaged the RGB values to recompose a smaller output image, we will compute the average depth of each new pixel. This depth will be used to position the voxels on the z axis of the cube.

This demonstration was made using a Kinect V2.
Walkthrough
If you have not already done so, I encourage you to read the last part of this series of tutorials as it explains how the algorithm used to downsize an image works.
Initial set-up
The following steps concern the Windows installation. For any other OS, please refer to this documentation.
Kinect SDK and drivers
First download the official SDK from Microsoft at this address.
Then you need to download this utility to install the alternative drivers used to communicate with processing: Zadig.
Finally follow these instructions in order to install the proper drivers.
Libraries
- L3D Library: the well-know.
- OpenKinect for Processing: allows to interact with the Kinect from processing.
The code
Link to the repository.
Server: Processing sketch
Link to the sketch.
Initialize the Kinect
Import the library and create a global variable for the Kinect.
import org.openkinect.processing.*; // Create kinnect object Kinect2 kinect;
Initialize the kinect in setup(), making sure to initialize the modules needed as well.
void setup() {
// initialize the Kinect and every module that we will use
kinect = new Kinect2(this);
kinect.initDepth(); // we need the depth information
kinect.initVideo(); // as well as the video from the webcam...
kinect.initRegistered(); // ... but we want the video that is aligned with the depth sensors
kinect.initDevice(); // finally start the device
}
Color image extraction
We use the same method employed with the webcam, except that we allow the user to provide a fraction of the original image as an input to be downsized.
This is done so that the area mapped to the cube can be made smaller than the default one, as such a wide area can map poorly when downsized especially when depth is involved.
We use the registered image and not the one straightly from the video because the first has been adjusted so that its orientation match the image from the IR camera, which is not the case with the latter.
First define the global variables that will hold the options.
int inSubsetSize = 256; // size of the subset of the original image to use int outSideSize = 8; // number of pixels per side on the output
Define a new getColorSubset() function. It is analog to the pixelateImage() we saw in the last part, except that it implements the new resizing functionality that we evoked.
PImage getColorSubset(int inSideSize, int outSideSize) {
PImage colorImg = kinect.getRegisteredImage();
colorImg.loadPixels();
PImage pOut = createImage(outSideSize, outSideSize, RGB);
pOut.loadPixels();
int pxSize = inSideSize/outSideSize;
int off_x = (kinect.depthWidth - inSideSize)/2;
int off_y = (kinect.depthHeight - inSideSize)/2;
colorImg = colorImg.get(off_x, off_y, inSideSize, inSideSize);
for (int x=0; x
Depth image extraction
The algorithm applied is the same, but this time on the greyscale image representing depth value returned by the IR camera. The original value lies between [0 ; 4500]. This image is composed of the correspondingly mapped greyscale value (range: [0 ; 255]).
We average this value over the delimited areas of the image and store it in an output image as the red value of the pixel.
Some values are discarded as they correspond to an unreachable depth and act as noise in the result.
PImage getDepthSubset(int inSideSize, int outSideSize) {
PImage depth = kinect.getDepthImage();
depth.loadPixels();
// Create and prepare output image
PImage pOut = createImage(outSideSize, outSideSize, RGB);
pOut.loadPixels();
// How many pixels of the input image are necessary to make
// the side of one pixel of the output image
int pxSize = inSideSize/outSideSize;
// the selected portion of the orginal image is selected
// by only retaining the pixels that fall into a centered square
// whose side's side is equal to the one provided in the first argument
int off_x = (kinect.depthWidth - inSideSize)/2;
int off_y = (kinect.depthHeight - inSideSize)/2;
depth = depth.get(off_x, off_y, inSideSize, inSideSize);
// loop through areas of the input image and run algorithm to extract
// average depth value
for (int x=0; x
UI Events
Same thing then with the webcam, but with a twist: we want to be able to toggle between the depth and color image view. This will be triggered by pressing any key on the keyboard.
First the state global variables.
... int mode1 = 0; // used to switch between 2D image and cube view int mode2 = 0; // used to switch between depth and color image ...
And the event listeners.
void mousePressed() {
if (mouseButton == RIGHT) {
mode1 = (mode1 == 1 ? 0 : 1);
}
}
void keyPressed() {
mode2 = (mode2 == 1 ? 0 : 1);
}
Rendering functions
Let's start by setting up everything for the cube.
import L3D.*;
...
// Create cube object;
L3D cube;
void setup() {
...
size(512, 512, P3D); // start simulation with 3d mode1 enabled
cube=new L3D(this); // init cube
}
Then continue with the function that will render the 2D image. Remember that it gives the possibility to display the depth or the color image, and that the depth will be displayed as a level of red.
void show2D(int inSize, int outSize) {
PImage image;
// toggle output image
if (mode2 == 0) {
image = getColorSubset(inSize, outSize);
} else {
image = getDepthSubset(inSize, outSize);
}
scale(512/outSize); // scale image object to fill the rendering screen
image(image, 0, 0); // display output image
}
Finally add the function that will render the kinect's output on to the cube. We generate two 8*8 output images from a 256 centered extract of the original images.
One of the image holds the colors and is used to set the color of the voxels. The other stores depth information as a level of red. This value is mapped on a [0 ; 7] range and used to position each voxel on the z axis of the cube.
void showCube() {
PImage depthImage = getDepthSubset(256, 8); // get depth info
PImage colorImage = getColorSubset(256, 8); // get color info
depthImage.loadPixels();
colorImage.loadPixels();
cube.background(0); // clear cube background
for(int x=0; x<8; x++)
for (int y=0; y<8; y++)
{
// map red value from depth image to a value that falls on the z axis
int z = round(map(red(depthImage.pixels[y+(x*8)]), 0, 255, 7, 0));
// display voxel
cube.setVoxel(x, 7-y, z, colorImage.pixels[y+(x*8)]);
}
}
Putting it all together
Populate the draw() loop with the rendering functions and the display options.
void draw() {
background(0); // set background to black
lights(); // turn on light
// toggle between 3D and 3D view
if (mode1 == 0) {
show2D(inSubsetSize, outSideSize);
} else {
showCube();
}
}
Client: Photon firmware
Upload the following code to your device.
Sources
- Kinect for Windows developer page.
- Getting started with Kinect and Processing from Daniel Shiffman.
- OpenKinect reference document.